Hadoop Ecosystem
Explore key components categorized for easy understanding. From data storage to seamless workflows, machine learning discover how Hive, HBase, Flume, and more contribute to the world of big data.
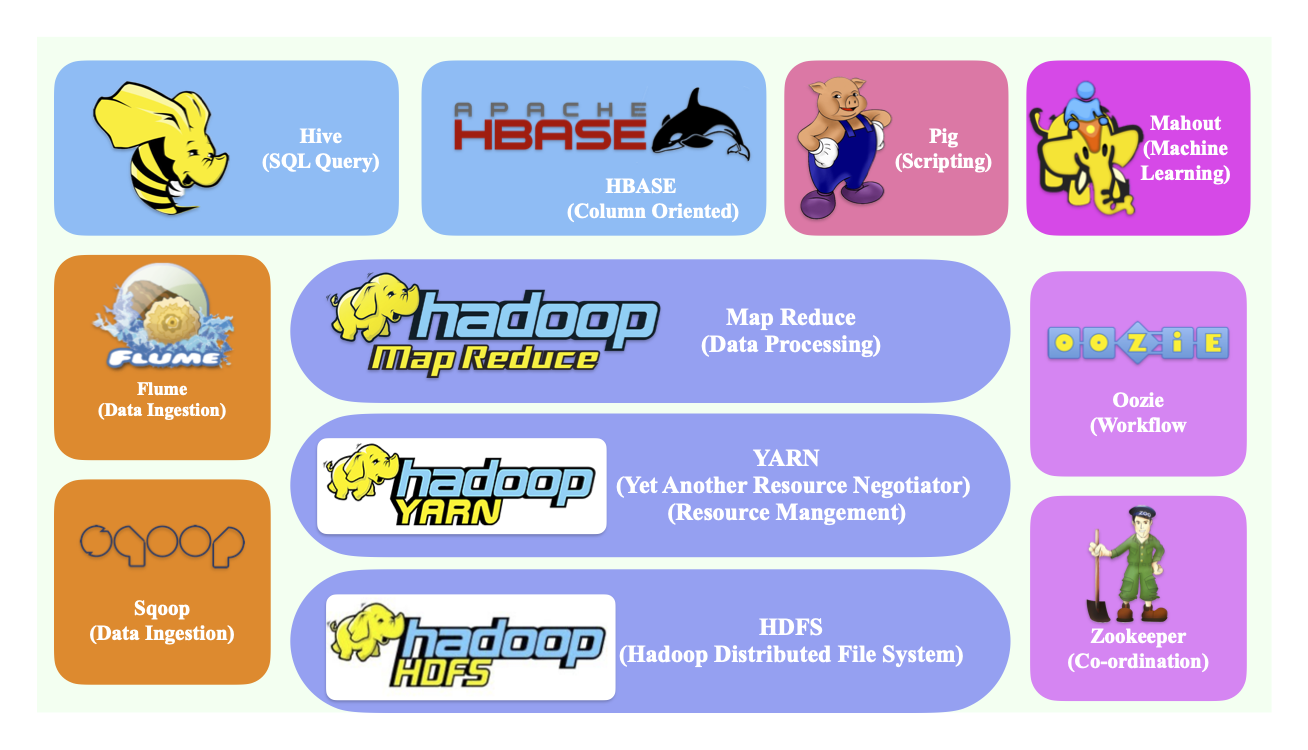
Hadoop Ecosystem
In the ever-evolving landscape of big data, the Hadoop ecosystem stands as a powerhouse, offering a robust framework for distributed storage and processing of vast amounts of data.
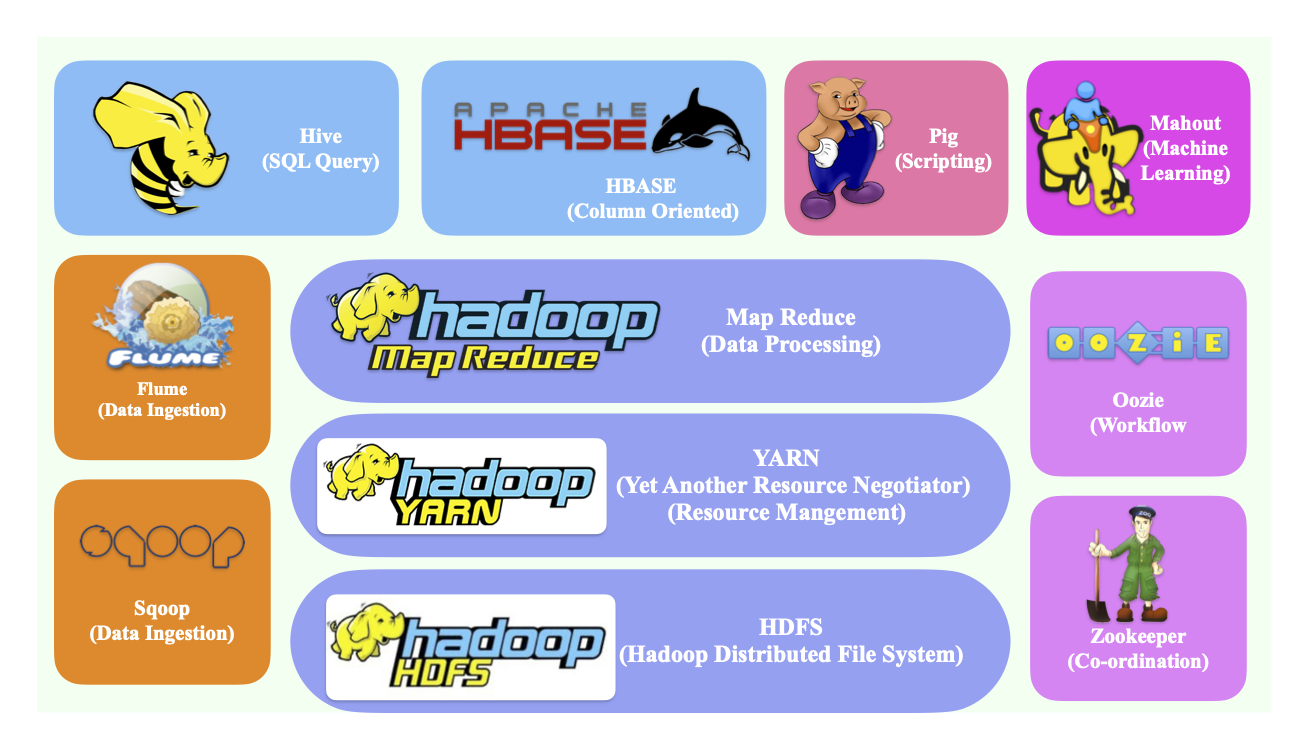
Key Components of the Hadoop Ecosystem
1. Data Ingestion and Transfer:
Flume: Seamless Streaming Data Collection
Flume is your data highway, ensuring a smooth flow of streaming data into the Hadoop ecosystem. It acts as the bridge connecting various data sources to Hadoop, working hand-in-hand with HDFS for efficient collection and transfer of streaming data.
Sqoop: Your Data Import/Export Wizard
Sqoop is like a data import/export superhero, helping you seamlessly move data between Hadoop and relational databases. Tightly integrated with Hadoop, Sqoop allows effortless transfer of data to and from HDFS, connecting Hadoop's distributed processing power with traditional relational databases.
2. Data Storage and Querying:
Hive: Your Gateway to Structured Big Data
Hive is like a translator for big data, allowing you to speak SQL and get meaningful insights from massive datasets. It simplifies data analysis by converting SQL-like queries into operations that Hadoop can understand, utilizing Hadoop Distributed File System (HDFS) for efficient storage and retrieval.
HBase: Real-Time NoSQL Database for Quick Access
HBase is your go-to solution for real-time access to large datasets without compromising on scalability. Integrated with Hadoop, HBase complements HDFS by providing fast and random read/write access to your data, making it suitable for low-latency operations.
3. Data Processing and Analysis:
Pig: Simplifying the Data Processing Journey
Pig is your scripting buddy, making data processing on Hadoop a breeze without the need for complex programming. Pig scripts abstract the intricacies of MapReduce programming, running on Hadoop to process large datasets stored in HDFS, enabling you to focus on the logic of your data transformations.
4. Machine Learning and Analytics:
Mahout: Unleashing Machine Learning on Big Data
Mahout is your ticket to the world of machine learning on big data, helping you make sense of vast datasets for predictive analytics and recommendations. Mahout seamlessly integrates with Hadoop, utilizing its parallel processing capabilities to efficiently execute machine learning algorithms on distributed datasets.
5. Workflow Coordination and Management:
Oozie: Orchestrating Workflows with Ease
Oozie is your workflow conductor, ensuring that Hadoop jobs dance in harmony according to a well-defined sequence. Oozie acts as the manager for workflows, coordinating the execution of various tasks in Hadoop, providing a structured way to manage and schedule complex data processing workflows.
6. Coordination and Consistency:
Zookeeper: Keeping Distributed Systems in Sync
Zookeeper is your guardian of coordination, ensuring that distributed systems within Hadoop remain in harmony. It plays a crucial role in maintaining coordination and consensus among different components in the Hadoop ecosystem, ensuring processes are synchronized, and data consistency is maintained.
7. Resource Management:
YARN: Efficient Resource Management for Hadoop
YARN is like a traffic manager for Hadoop, efficiently allocating resources to different applications running on the cluster. YARN enhances the performance of Hadoop by managing resources dynamically, allowing various processing engines, including MapReduce, to share resources effectively and optimize overall cluster performance.
The Hadoop ecosystem is a vast and interconnected landscape that empowers organizations to handle big data challenges effectively. From storage and ingestion to processing, analysis, and workflow management, each component plays a crucial role in simplifying the complex journey of turning raw data into valuable insights. 🚀🔍
Video Reference:
{{< youtube 8r7kHT4K1pA >}}
On this page
Keep exploring
matched by tag + title overlap
Read next
Introduction to Hadoop
Breaking down Big Data basics! 📊 Explored structured, unstructured, and semi-structured data. 📊 Explored big data challenges and solutions, spotlighting HDFS and MapReduce Architecture.
#data-engineering#apache-hadoop#apache-sparkSQL Interview Quick Guide: From Basics to Interview Ready
Whether you're a beginner or looking to polish your skills, this blog post breaks down essential SQL concepts with clear explanations and practical examples of potential SQL interview questions. Prepare to your next SQL interview!
#data-engineeringAzure Data Factory: Microsoft Cloud Data Integration Tool
Azure Data Factory is Microsoft's cloud-based service for orchestrating and automating data movement and transformation. It offers data integration from various sources, supports complex ETL processes, and enables efficient workflow…
#data-engineeringWhat is Data Modeling - Normalization, and Application in OLTP Systems
Explore the essentials of Data Modeling in this article, which covers key types (Conceptual, Logical, Physical) and techniques like ER Modeling and Normalization. It highlights normalization's role in databases, particularly in OLTP systems
#data-engineering